在数字化信息广泛传播的今天,各类文字编码技术扮演着至关重要的角色。然而,在实际使用中,尤其是在处理中文、日文、韩文等中日韩文字时,常常会遇到“乱码”的问题。这些乱码现象背后隐藏着复杂的字符编码机制及不同语言的编码标准。本文将从中日韩字符编码的区别入手,解析乱码产生的原因,以及应对乱码的基本策略,帮助读者深入理解字符编码的难题与破解方法。
一、中日韩文字编码的基础知识
字符编码是将字符与计算机内部数字代码对应起来的标准。最早的ASCII编码只涵盖英文字符,对于汉字、日文假名、韩文字等扩展字符集,后续发展出了多种编码标准。中文、日文、韩文(简称CJK)字符占用的空间广泛,因此存在多种专门的编码方案,如GB2312、GBK、Big5、Shift_JIS、EUC-KR等。

GB2312和GBK主要应用于简体中文环境,支持大量汉字;Big5是繁体中文主要编码标准;Shift_JIS和EUC-KR则是日文和韩文常用的编码方式。每种编码都在字符集、编码范围和存储方式上有所不同,因此交叉兼容存在困难,也为乱码问题埋下隐患。
二、不同编码标准带来的区别
中日韩字符编码虽都属于CJK编码体系,但在编码范围、字符映射、编码结构上存在显著差异。例如,Shift_JIS采用的字节范围与GBK不同,它部分字符占用两个字节,但编码值不同,导致在数据跨平台传输或测试时容易出现乱码。而EUC-KR支持韩文字集,但与GBK不兼容,二者在存储或显示过程中可能产生字符错位或显示乱码。
此外,一些编码标准还采用不同的字符排序和编码规则。例如,汉字在GB2312中的排序方式与Big5存在差异,这在字符检索、排序时可能引发问题。此外,随着UTF-8成为国际通用的编码标准,支持所有CJK字符,但在老旧系统中依然存在编码不兼容和乱码问题。
三、乱码的产生原因
乱码主要源于编码不一致。比如,将用GBK编码的文件在未正确声明或转换为UTF-8后打开,出现字符变形的情况。此外,字符集缺失或字符不能被正确识别也容易导致乱码。而在浏览网页或处理文档时,如果编码声明与实际文件编码不匹配,浏览器或软件无法正确解析字符,就会显示乱码。
另一主要原因是字符集中的字符编码缺失。例如,部分老旧系统未支持新兴编码或缺少某些字符的映射关系,也会导致显示错误。再者,数据传输过程中的编码转换错误、文件保存时的编码设置不一致,都可能造成乱码问题。
四、辨别和解决乱码的方法
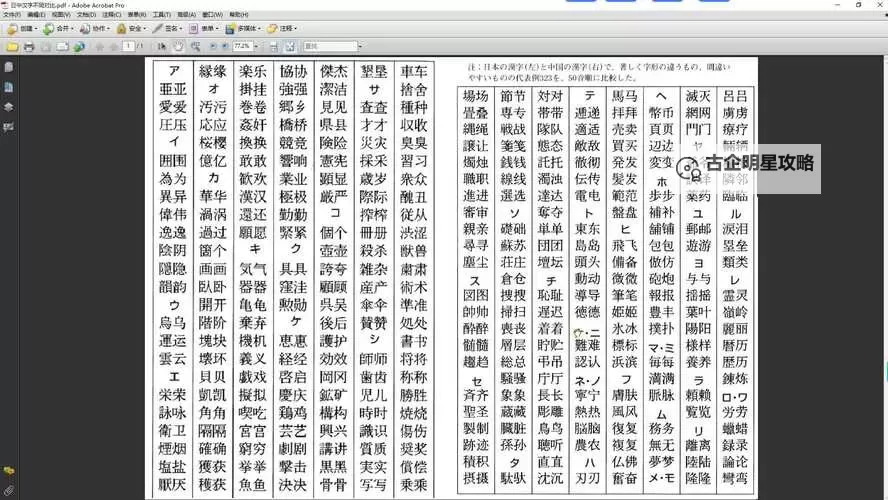
要解决乱码问题,首先需要确定文本的实际编码。可以通过打开文件时选择不同编码,结合字符的正确显示,找到最匹配的编码标准。对于网页,检查页面的``标签中的字符集声明是否正确,也是关键步骤。如果没有声明或声明错误,应手动更改为正确编码。
此外,使用支持多编码的文本编辑器或专业的编码检测工具,也有助于识别文本编码。同时,转换编码时应选用正确的字符集,比如将GBK转换为UTF-8,确保数据一致性。对于批量转换,可以借助编码转换工具或脚本进行处理,避免手工操作出错。
在编码转换之前,最好备份原始文件以预防数据丢失。在日常开发和数据交换中,采用UTF-8编码已成为最佳实践,兼容性强,能够支持中日韩的全部字符集,有效减少乱码发生的概率。
五、未来展望——标准化与兼容性提升
随着国际化标准的提高,Unicode(尤其是UTF-8)逐渐成为中日韩文字的统一编码方案。Unicode为所有语言字符提供了统一的编码空间,大幅度减少了乱码问题。然而,历史遗留的编码标准依然在许多场合被使用,导致字符兼容性问题持续存在。未来,应推动旧有标准的淘汰和UTF-8的普及,增强系统的编码兼容性,减少乱码产生,从根本上解决中日韩字符编码的难题。
总之,了解中日韩字符编码的区别及其背后的技术原理,是有效避免和解决乱码问题的基础。通过合理选择编码标准、正确识别编码方式,以及使用标准化、统一的字符编码方案,可以大大提升文字信息的准确性与交流效率。在信息时代,掌握字符编码的知识,无疑是每个从事相关工作的人员必备的技能之一。